Module 1: Introduction
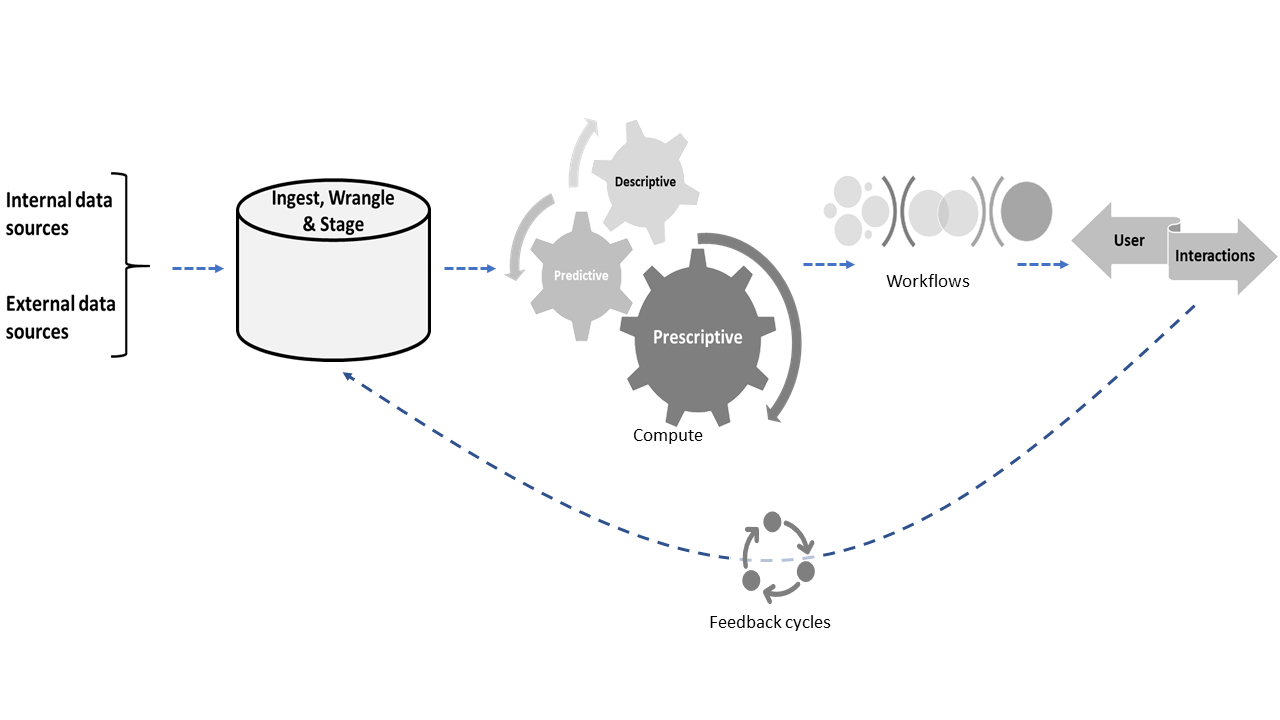
We review how Data Products have been variously defined, the scope of this course (and how it builds upon and complements topic specific courses), and recapitulates some basics of relational data storage (using SQLite).
This course takes an expansive view of data products comprising raw & derived data, algorithms & models, decision support & recommendation systems and automation; looking at the challenges and corresponding practical solutions and the underlying principles essential for developing such products. Topics covered span the life-cycle of data products, spanning many basic as well as advanced and important elements of typical data-pipelines, including ETL (Extract, Transform, Load) processes, visualization, dashboards & UI issues, statistical tools for ML/NLP, validation of results & robustness of ML models, integration with back-end big-data & NoSQL systems, e.g., MongoDB, Neo4j, data governance issues and their privacy & regulatory compliance implications.

This course has been created for and offered to the third and fourth year undergraduate students in NTU's degree programme in Data Science and Artificial Intelligence (DSAI) offered jointly by the School of Computer Science and Engineering (SCSE) and the School of Physical and Mathematical Sciences (SPMS). Hands-on in its treatment, projects in the course, some carried out individually and one in groups, expose the students to end-to-end data product development and data-pipelines with real world complexity; while ungraded programming tasks scattered across the modules provide opportunities to challenge themselves in mastering a wide range of practical and popular tools and techniques.
The material provided here is suitable for individuals who are already well versed in programming (I primarily use tools from the Python ecosystem) and who have prior exposure to basic concepts of statistics, data science and machine learning, and wish to put these skills together in a principled manner using practical and state-of-the-art tools holistically in designing and developing data-products involving real-world data, systems and complexity. As such, prior indepth knowledge to aspects of Databases, Machine Learning, Natural Language Processing, Network Science are desirable (though not essential as long as the students can catch-up on the underlying concepts on thier own). In particular, the objective of this course is not to teach any particular programming language, algorithms or tools per se, even though specific artefacts are used for concrete instantiation and realization of the ideas and concepts, and as such some background and preliminaries are reviewed as and when needed, for making the content reasonably self-contained.
Most modules are presented with HTML slides that intermingle conceptual content with hands-on code snippets. Some modules have PDF slides focussing on conceptual aspects. IPYNB Jupyter notebooks contain the code and source material which were used for creating the HTML slides.
We review how Data Products have been variously defined, the scope of this course (and how it builds upon and complements topic specific courses), and recapitulates some basics of relational data storage (using SQLite).

In this module we explore some basic concepts of Pandas - DataFrame, Apply, Lambdas, Merge, Groupby, Missing data, etc., and regular expressions (RegEx) for data cleaning.
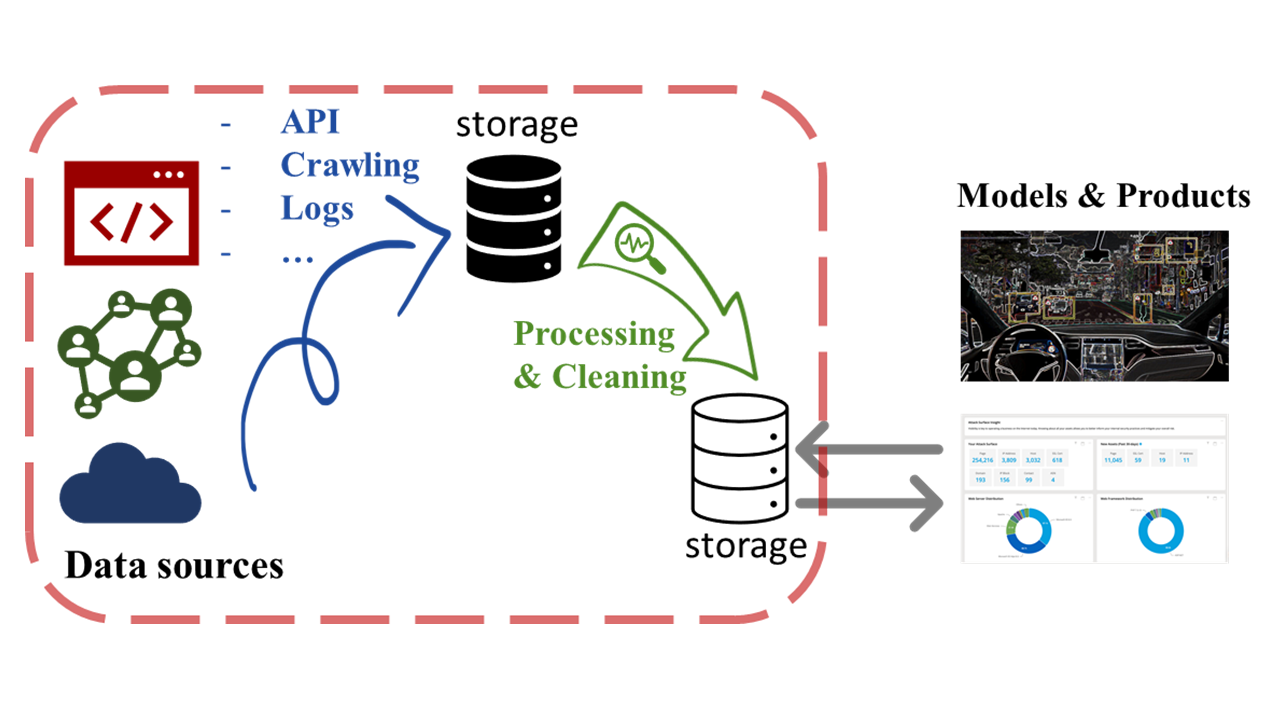
In this module we look into acquisition of data by various means including web scraping and APIs, parsing data with tools such as BeautifulSoup, storing and working with JSON data objects, e.g., with MongoDB Atlas Database.

Norms of good visualization and bad (in terms of aesthetics, ambiguity, truthfullness, etc.) are discussed with examples serving as a directory of visualizations. Accessibility, particularly for colorblind people is also edified.
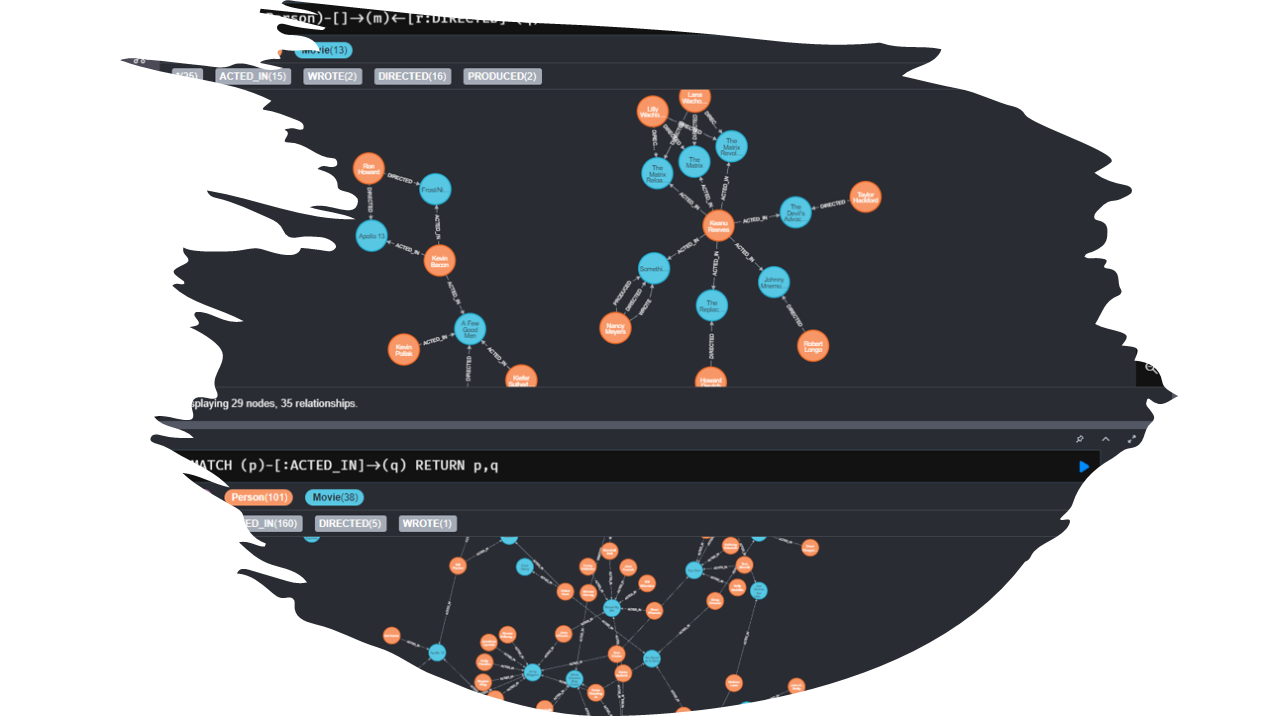
Graph data and associated algorithms (e.g., centrality, community detection, link prediction) are expounded with NetworkX. Graph database and Cypher Query Language is explored using Neo4j AuraDB.
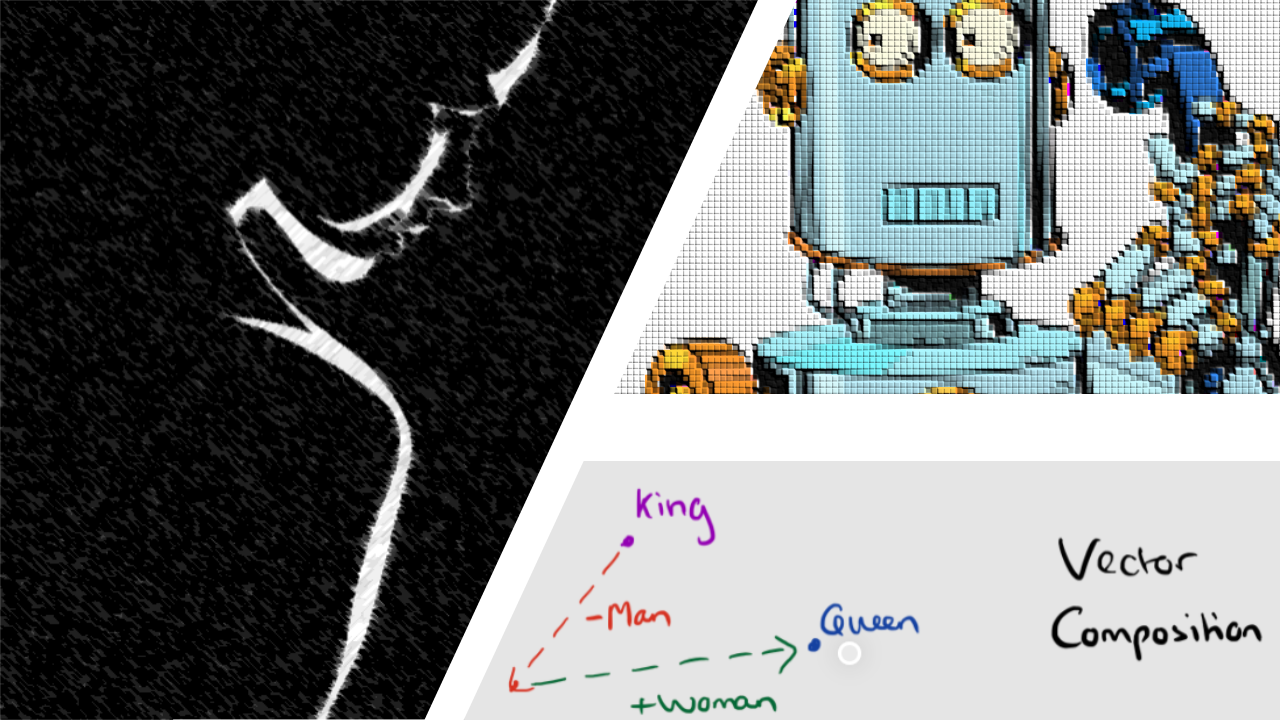
Essential Natural Language Processing concepts are investigated, complemented by the application of Machine Learning techniques with the emphasis on how to use, evaluate and interpret ML algorithms/outputs properly.
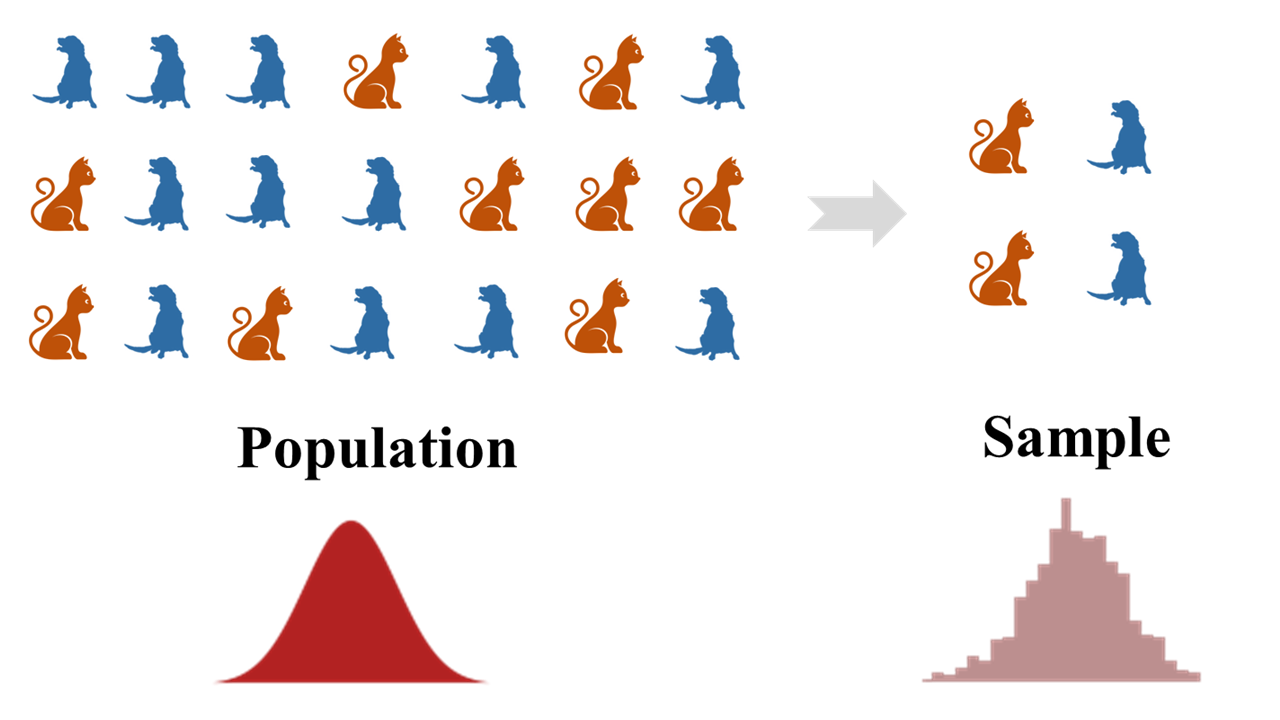
We study the ideas of sampling, statistical experiments and significance, exploring them experimentally - in contrast to the typical extremes of rigorous mathematical analysis or a complete black-box treatment of the topics.
The concepts of data lineage, quality, regulatory compliance are briefly discussed, accompanied with a more in-depth examination of different anonymity models and techniques, e.g., k-anonymity, l-diversity and differential privacy.
The data used in all the module codes are provided together as a .zip archive. The data path in the codes need to be adjusted for the codes to work.